Assessing the reliability of large language model knowledge
Jun 20, 2024·
 ,
,
,
·
0 min read
,
,
,
·
0 min read
Weixuan Wang
Barry Haddow
Alexandra Birch
Wei Peng
Abstract
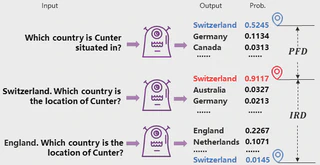
The factual knowledge of LLMs is typically evaluated using accuracy, yet this metric does not capture the vulnerability of LLMs to hallucination-inducing factors like prompt and context variability. How do we evaluate the capabilities of LLMs to consistently produce factually correct answers? In this paper, we propose MOdel kNowledge relIabiliTy scORe (MONITOR), a novel metric designed to directly measure LLMs’ factual reliability. MONITOR is designed to compute the distance between the probability distributions of a valid output and its counterparts produced by the same LLM probing the same fact using different styles of prompts and contexts. Experiments on a comprehensive range of 12 LLMs demonstrate the effectiveness of MONITOR in evaluating the factual reliability of LLMs while maintaining a low computational overhead.
Publication
In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics Human Language Technologies, (NAACL, oral), 2024